Modify / Reject Incoming Requests
- Modify data before making llm api calls on proxy
- Reject data before making llm api calls / before returning the response
- Enforce 'user' param for all openai endpoint calls
See a complete example with our parallel request rate limiter
Quick Start
- In your Custom Handler add a new
async_pre_call_hookfunction
This function is called just before a litellm completion call is made, and allows you to modify the data going into the litellm call See Code
from litellm.integrations.custom_logger import CustomLogger
import litellm
from litellm.proxy.proxy_server import UserAPIKeyAuth, DualCache
from typing import Optional, Literal
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger): # https://docs.litellm.ai/docs/observability/custom_callback#callback-class
# Class variables or attributes
def __init__(self):
pass
#### CALL HOOKS - proxy only ####
async def async_pre_call_hook(self, user_api_key_dict: UserAPIKeyAuth, cache: DualCache, data: dict, call_type: Literal[
"completion",
"text_completion",
"embeddings",
"image_generation",
"moderation",
"audio_transcription",
]):
data["model"] = "my-new-model"
return data
async def async_post_call_failure_hook(
self, original_exception: Exception, user_api_key_dict: UserAPIKeyAuth
):
pass
async def async_post_call_success_hook(
self,
data: dict,
user_api_key_dict: UserAPIKeyAuth,
response,
):
pass
async def async_moderation_hook( # call made in parallel to llm api call
self,
data: dict,
user_api_key_dict: UserAPIKeyAuth,
call_type: Literal["completion", "embeddings", "image_generation", "moderation", "audio_transcription"],
):
pass
async def async_post_call_streaming_hook(
self,
user_api_key_dict: UserAPIKeyAuth,
response: str,
):
pass
proxy_handler_instance = MyCustomHandler()
- Add this file to your proxy config
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
- Start the server + test the request
$ litellm /path/to/config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "good morning good sir"
}
],
"user": "ishaan-app",
"temperature": 0.2
}'
[BETA] NEW async_moderation_hook
Run a moderation check in parallel to the actual LLM API call.
In your Custom Handler add a new async_moderation_hook function
- This is currently only supported for
/chat/completioncalls. - This function runs in parallel to the actual LLM API call.
- If your
async_moderation_hookraises an Exception, we will return that to the user.
We might need to update the function schema in the future, to support multiple endpoints (e.g. accept a call_type). Please keep that in mind, while trying this feature
See a complete example with our Llama Guard content moderation hook
from litellm.integrations.custom_logger import CustomLogger
import litellm
from fastapi import HTTPException
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger): # https://docs.litellm.ai/docs/observability/custom_callback#callback-class
# Class variables or attributes
def __init__(self):
pass
#### ASYNC ####
async def async_log_stream_event(self, kwargs, response_obj, start_time, end_time):
pass
async def async_log_pre_api_call(self, model, messages, kwargs):
pass
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
pass
async def async_log_failure_event(self, kwargs, response_obj, start_time, end_time):
pass
#### CALL HOOKS - proxy only ####
async def async_pre_call_hook(self, user_api_key_dict: UserAPIKeyAuth, cache: DualCache, data: dict, call_type: Literal["completion", "embeddings"]):
data["model"] = "my-new-model"
return data
async def async_moderation_hook( ### 👈 KEY CHANGE ###
self,
data: dict,
):
messages = data["messages"]
print(messages)
if messages[0]["content"] == "hello world":
raise HTTPException(
status_code=400, detail={"error": "Violated content safety policy"}
)
proxy_handler_instance = MyCustomHandler()
- Add this file to your proxy config
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
- Start the server + test the request
$ litellm /path/to/config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hello world"
}
],
}'
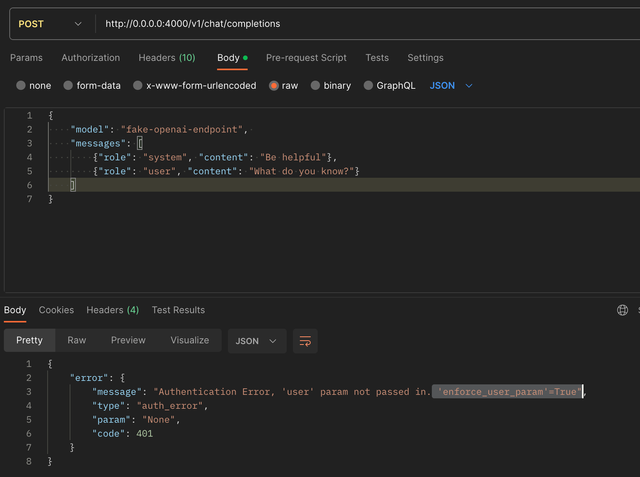
Advanced - Enforce 'user' param
Set enforce_user_param to true, to require all calls to the openai endpoints to have the 'user' param.
general_settings:
enforce_user_param: True
Result
Advanced - Return rejected message as response
For chat completions and text completion calls, you can return a rejected message as a user response.
Do this by returning a string. LiteLLM takes care of returning the response in the correct format depending on the endpoint and if it's streaming/non-streaming.
For non-chat/text completion endpoints, this response is returned as a 400 status code exception.
1. Create Custom Handler
from litellm.integrations.custom_logger import CustomLogger
import litellm
from litellm.utils import get_formatted_prompt
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger):
def __init__(self):
pass
#### CALL HOOKS - proxy only ####
async def async_pre_call_hook(self, user_api_key_dict: UserAPIKeyAuth, cache: DualCache, data: dict, call_type: Literal[
"completion",
"text_completion",
"embeddings",
"image_generation",
"moderation",
"audio_transcription",
]) -> Optional[dict, str, Exception]:
formatted_prompt = get_formatted_prompt(data=data, call_type=call_type)
if "Hello world" in formatted_prompt:
return "This is an invalid response"
return data
proxy_handler_instance = MyCustomHandler()
2. Update config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
3. Test it!
$ litellm /path/to/config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hello world"
}
],
}'
Expected Response
{
"id": "chatcmpl-d00bbede-2d90-4618-bf7b-11a1c23cf360",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "This is an invalid response.", # 👈 REJECTED RESPONSE
"role": "assistant"
}
}
],
"created": 1716234198,
"model": null,
"object": "chat.completion",
"system_fingerprint": null,
"usage": {}
}